After years of running complex operations, I learned the hard way that dashboards don’t keep promises—teams do. What changed everything was adopting “managing by exception”: letting AI surface only the moments that truly threaten customer trust and revenue, and acting early. This piece shares what that shift looks like in practice—and how to build a calmer, more predictable operating cadence without adding headcount.
Introduction: Harnessing AI for Proactive, Managing by Exception in Complex Workflows
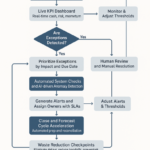
AI makes managing-by-exception real: it watches every workflow, surfaces only threats to service-level agreements (SLAs), revenue, and trust, and enables action before impact.
- Risk scoring flags bottlenecks and SLA drift; owners see business impact, not noise.
- Correlation across tools isolates root cause in minutes and automates triage and escalation.
- Forecasted workload and capacity hotspots protect delivery without extra headcount or dashboards.
- Audit-ready trails and clear ownership reduce compliance exposure and process drift.
Net result: lower mean time to detect (MTTD) and mean time to resolve (MTTR), a steadier cadence, and more time for growth. For calm, practical insight, Lyaxis’ weekly brief unpacks real exception patterns—use it to pressure-test your operating model.
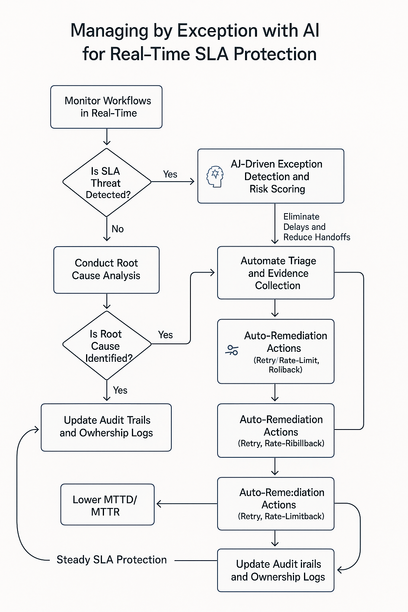
Real-Time Monitoring and AI-Driven Exception Management: Detecting Bottlenecks and SLA Risks Early
Real-time monitoring matters when delays cost revenue and trust. AI-driven exception management surfaces weak signals before they become SLA misses.
- Correlate tickets, queues, and application programming interface (API) latency (e.g., regional checkout spikes) to reveal the bottleneck, not the noise.
- Policies score impact and confidence, route the right owner, and timestamp accountability.
- Explainable detections attach root-cause clues, shrinking false positives and handoffs.
- Smart actions auto-retry, rate-limit, or rollback; escalations arrive with context.
Lyaxis applies this philosophy so operations stay quiet and predictable. For patterns and benchmarks that cut MTTD/MTTR and protect SLAs—without adding headcount, our newsletter offers the signal—not more alerts.
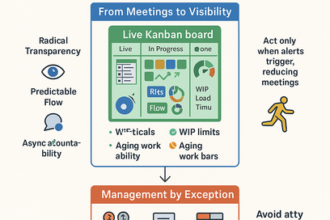
Overcoming Operational Blind Spots: Achieving Cross-System Visibility and Reducing Alert Fatigue
Blind spots across tools keep leaders reactive. AI-driven correlation enables managing by exception—before customers notice.
- Unify tickets, logs, and revenue signals to map dependencies and surface hidden bottlenecks.
- Tie alerts to SLAs and impact; suppress duplicates; present one actionable exception with likely root cause.
- Automate triage and ownership with intelligent routing to cut MTTD/MTTR and handoffs.
- Forecast risk via anomalies and capacity trends so you intervene early without adding headcount.
Want practical patterns and benchmarks? Lyaxis briefings show how peers cut noise and raise reliability—insight you can use. Outcome: fewer pages, protected SLAs, and time back for strategy.
From Firefighting to Strategy: Automating Triage, Escalation, and Root Cause Analysis with AI
AI can run first-pass triage, routing, and evidence gathering so you manage by exception, not dashboards. That means earlier warnings, cleaner escalations, and time back for prevention.
- Real-time anomaly detection flags SLA risk by customer and revenue impact, not noise.
- Automated triage assembles evidence—logs, traces, tickets—so the first human sees context.
- Intelligent routing assigns ownership and next actions, avoiding ping‑pong.
- Cross-tool correlation surfaces likely root causes in minutes, cutting MTTD/MTTR.
Curious how this works? The Lyaxis newsletter shares field notes you can apply; when it clicks, Lyaxis can wire it into your stack. Fewer fires, steadier growth.
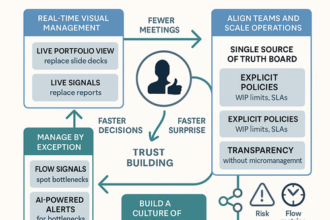
Building a Predictable, Scalable Operating Cadence Without Adding Headcount
Predictable scale comes from a calm cadence—run by signals, not status meetings. AI makes it real by surfacing only the exceptions that matter, before customers notice.
- Real-time leading indicators unify tool data to flag bottlenecks, SLA risk windows, and anomalies.
- Automated triage and smart escalation assign owners, score risk, propose root cause, and trigger playbooks with quantified revenue/SLA impact.
- Lightweight governance adds weekly service-level objective (SLO) reviews, drift alerts, and audit trails—no new dashboards.
Curious? Lyaxis distills exception patterns and benchmarks in a short newsletter you can apply anywhere. Net: lower MTTD/MTTR, steadier throughput, and reliability without extra headcount—or stress.