Introduction: Aligning Escalation Triggers to Safeguard SLAs
After years of carrying the pager, I learned the hard way that calm operations come from clarity, not heroics. The moment we aligned escalation triggers to what our SLA (Service Level Agreement) actually promised customers—instead of what noisy tools were shouting—risk showed up earlier, decisions got simpler, and teams slept better.
Escalations should mirror what your SLA promises, not what your tools shout. When triggers reflect customer impact and error budgets, you spot risk early and act calmly.
- Anchor thresholds to business outcomes—response time, backlog age, churn risk—not raw system noise.
- Use error‑budget burn rate and time‑to‑violation as early alarms, not last‑minute pages.
- Assign single‑threaded owners per trigger with clear cross‑function handoffs.
- Automate routing to runbooks, so resolution scales without heroics.
- Expose a live “breach likelihood” dashboard to cut debate and drive action.
Lyaxis can map SLAs to impact signals; our newsletter unpacks the how. Outcome: fewer breaches, less firefighting.
Defining Clear Thresholds and Ownership to Prevent SLA Breaches
With principles in place, the next step is to set crisp guardrails and single ownership so breaches become rare—and predictable.
SLA breaches start with fuzzy lines and shared ownership. Replace both with crisp thresholds and a single-threaded owner per stage.
- Set business-backed limits: backlog >25 or VIP (Very Important Person/customer) first-response >3 min triggers P1 (Priority 1) risk.
- Make handoffs explicit: incident lead to resolver to comms, with on-call backup.
- Route by impact, not chatter: burn rate >2x or churn risk auto-escalates.
- Codify runbooks that scale and auto-close loops.
Want clean guardrails? Lyaxis maps thresholds, owners, and routes; our newsletter shares patterns to test now—templates and drills when you’re ready. Net: fewer breaches, calmer ops (operations), faster growth.
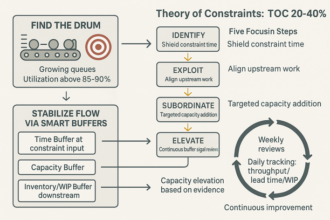
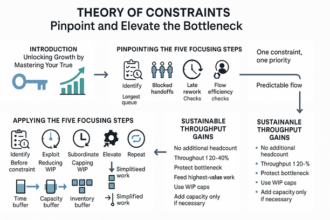
Designing Scalable Escalation Matrices and Runbooks for Consistent Response
Once thresholds and owners are clear, scale them with a matrix and runbooks that make action obvious long before the clock turns red.
- Triggers: SLO-driven (Service Level Objective–driven) thresholds fire at 70–80% risk (latency, backlog minutes, error spikes) to act before breach.
- Ownership: One incident owner; preapproved handoffs by product and time zone; decision trees end debate.
- Automation: KPIs (Key Performance Indicators) drive paging and routing; dedupe noise; rank by customer impact; surface time-to-breach.
- Rhythm: Lightweight runbooks and rosters; weekly 20-minute review; quarterly matrix refresh tied to churn signals.
Lyaxis brings templates and cadences; our newsletter reveals the patterns to cut breaches and reclaim focus.
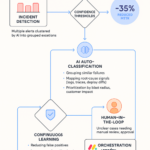
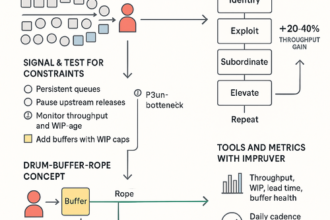
Leveraging Automation and Early-Warning Dashboards to Cut Alert Fatigue
Automation turns your matrix into momentum: fewer pings, clearer ownership, and action that starts before customer pain.
- Correlate signals into one incident and suppress flapping; make alerts SLO‑aware so error‑budget burn, not noise, drives pages.
- Auto‑route via an escalation matrix and runbooks tied to business impact, not channels.
- Use leading KPIs—queue wait, retry spikes, backlog age—to start pre‑breach plays.
- Show “time‑to‑breach,” owner, and next action on one board so leaders stay out.
Want the patterns? Lyaxis’ newsletter unpacks them; tools follow. For structured upskilling that complements these practices, consider Impruver University.
Takeaway: quieter ops (operations), fewer breaches, faster recovery.
Building Accountability Without Heroics: Leadership Relief Through Standardized Escalation
Finally, make accountability boring. Heroics are design debt. Escalation should be predictable—so leaders can focus on outcomes, not firefights.
- Define pre-breach thresholds tied to business impact; trigger before customer pain.
- Name a single-threaded owner per incident class; handoffs follow a matrix.
- Automate routing from KPIs to the right team; kill manual triage and Slack roulette.
- Tune signals to reduce noise; dashboards surface SLA risk before breach.
- Close the loop with blameless reviews and updated runbooks that scale onboarding.
Want relief without drama? Lyaxis shares trigger-to-owner patterns and templates via our newsletter—insights first, help when you’re ready. The payoff: fewer breaches, calmer leaders, steadier growth.