Introduction: Why Invisible Work Is Sabotaging Your Team’s Focus
I learned the hard way that our biggest drag wasn’t skill—it was the work we couldn’t see. A week that looked calm on the roadmap would implode by Wednesday: Slack pings, “got a sec?” favors, and hallway asks quietly hijacked the plan. When I finally made those interrupts visible, two things happened: our capacity got honest, and focus returned.
Your team’s biggest drag isn’t skill; it’s invisible work. Untracked pings and “got a sec?” tasks sap attention, hide capacity, and derail plans. The fix starts with treating interrupts as real work and giving them a place to live—right on your Kanban board. As you go, define key terms up front so everyone speaks the same language:
- Make interrupts first‑class – Route Slack pings to a Kanban intake so every favor gets a card.
- Quantify the stream – Capture arrival rate and SLAs (Service Level Agreements, the response times you promise) to expose hidden demand and end overbooking.
- Protect focus – Use WIP (Work‑In‑Progress) limits and a simple “front desk” to absorb noise while builders stay in flow.
- Reset expectations – Make trade‑offs visible to raise trust and cut firefighting.
Make it visible so accuracy and leadership focus return. For practical, copy‑ready patterns, I share field notes in the Lyaxis newsletter. If you want a deeper dive with a structured path, explore Impruver University (often with promotions like “15off”).
Seeing the Unseen: Using Kanban to Capture Interruptions and Quick Requests
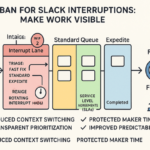
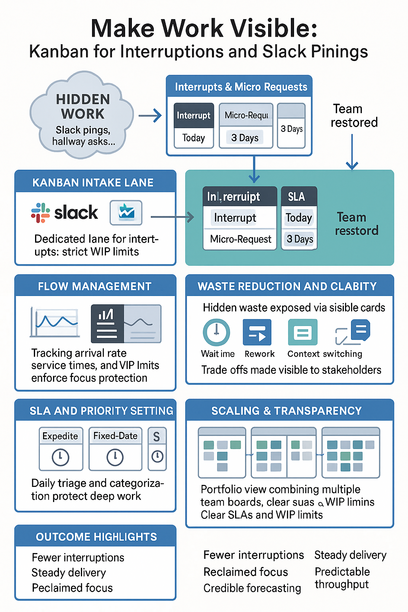
What if the real overload is invisible work? Kanban makes interrupts visible—and negotiable. Start by giving every ping a doorway and a label so it can be sized, tracked, and traded against other commitments.
- Add an Interrupt lane with strict WIP – Funnel Slack asks via one emoji or a short form so noise converges into a single queue.
- Label work types – Use simple tags like “Interrupt” and “Micro‑Request,” then set two SLAs—“today” or “three days”—so pings become clear expectations, not emergencies.
- Track arrivals and service – Monitor arrival rate, service time, and percent unplanned; patterns replace firefighting and planning improves.
When interrupts are seen, capacity becomes a choice—and focus returns.
From Chaos to Clarity: Reducing Slack Pings and Exposing Hidden Waste with Kanban
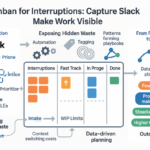
Slack can feel like a fire alarm. Kanban converts chaos into clear pull signals, turning a stream of pings into an orderly, transparent intake.
- One intake lane – Turn pings into sized, dated cards so calm returns and nothing “disappears.”
- Boards expose hidden taxes – Surface wait time, rework, and handoff friction—the real cost of context switching.
- WIP limits and SLAs protect focus – Stakeholders see trade‑offs, not excuses, and choose what moves next.
- Lookbacks turn data into decisions – Quantify interrupts to tune capacity, pricing, and the roadmap.
Outcome: fewer pings, clearer commitments, predictable throughput.
Protecting Focus and Improving Flow: Setting SLAs and Priorities for Ad‑Hoc Work
Ad‑hoc work doesn’t have to hijack your roadmap. A few lightweight guardrails keep the team in flow while making response times explicit.
- Channel pings into a single intake – One Kanban entry point reveals hidden demand and reduces DM thrash.
- Define classes of service – Use “Expedite,” “Fixed‑Date,” and “Standard” so response time is understood before work starts.
- Set tiny SLAs per class – Triage daily and let data answer “how soon?” instead of relying on heroics.
- Use WIP limits to protect deep work – Queue the rest so makers get uninterrupted time.
- Measure cycle time by class – Cycle time is the elapsed time from start to finish; use it to set realistic forecasts.
Result: fewer pings, steadier delivery, and reclaimed focus—without adding headcount.
Sustaining Predictability: Scaling Operations with Transparent Work and Reliable Planning
When every ping is visible, predictability scales. Interrupts flow through one system, and your capacity—and promises—stay honest across teams.
- Route Slack pings to intake – Track arrival rate and aging to expose hidden demand before it burns time.
- Connect team boards to a portfolio view – Surface dependencies early so cross‑team commitments move cleanly.
- Set classes of service with simple SLEs – SLEs (Service Level Expectations) are data‑based expectations for how fast work finishes; pair them with WIP limits to cut switching.
- Review demand vs. throughput weekly – Throughput is items finished per time period; tune cadence and forecast with real interrupt data.
The payoff is fewer pings and credible forecasts you can stake your reputation on.
If you’d like a short, actionable setup you can copy, grab the patterns in the Lyaxis newsletter. To go deeper with structured, practice‑ready lessons, check out Impruver University (look for discounts like “15off”).