Introduction: Designing Escalation Processes That Free Leadership and Protect Revenue
After years running customer operations and product on-call, the weeks that felt calmest weren’t the ones with zero incidents—they were the ones where our escalation path worked like a control system. Signals routed cleanly, one person made the tough tradeoffs, customers got timely updates, and leaders weren’t dragged into every thread. That’s the goal of this playbook: build an escalation design that protects revenue, earns trust, and gives executives their time back.
Escalations should be a designed control system, not executive theater. Build a path that routes the right signal fast, protects revenue, and frees leaders.
Want patterns, not firefighting? Lyaxis shares battle-tested escalation archetypes in our newsletter; Impruver University adds role-based drills. Net: fewer exec pings, faster resolution, lower churn risk.
Mapping Clear Escalation Paths: Defining Triggers, Severities, and Ownership
Escalations shouldn’t need executives; they need a designed path that moves fast. Make the first move automatic with crisp triggers, tiers, and a single owner.
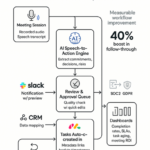
- Triggers: Objective thresholds by impact, scope, and time (for example, more than $50k Annual Recurring Revenue (ARR), more than 10% of users affected, data or legal risk).
- Severities + Service Level Agreements (SLAs): Severity 1 (S1) page in 5 minutes/restore in 2 hours; Severity 2 (S2) page in 30 minutes/restore in 8 hours; any breach auto‑escalates.
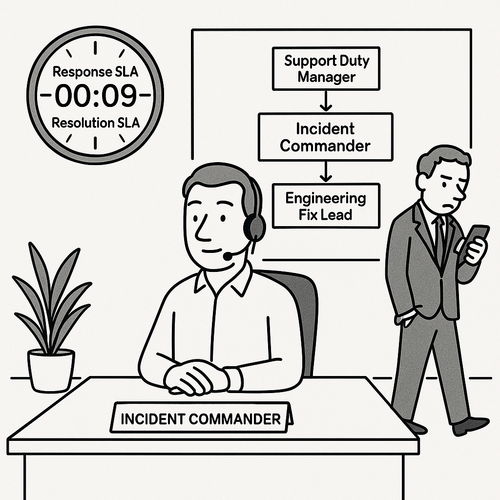
- Ownership: One Incident Commander (IC) owns the incident; Engineering (Eng) and Customer Success (CS) leads run workstreams; communications every 30–60 minutes.
- Flow + metrics: Support Duty Manager (DM) → IC → Eng Fix Lead; track Time to Resolve (TTR), communications cadence, Root Cause Analyses (RCAs); review weekly.
Clear triggers and severities mean objective thresholds by impact, not emotion. Assign a single owner per case—empowered to marshal teams and decide tradeoffs—with time‑boxed SLAs, visible clocks, and automatic next‑step escalation.
Setting SLAs That Stick: Balancing Realistic Response and Resolution Times
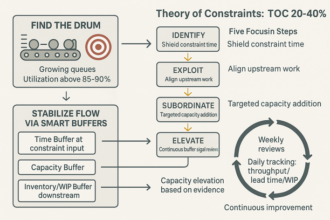
SLAs that survive load turn escalations from chaos into predictable work. Separate what you promise to do first from when you will fix it—and make the clocks unambiguous.
- Separate response and resolution: Acknowledge in minutes; fix by severity‑driven targets that customers believe. Response time is your Time to Acknowledge (TTA); fix time is your TTR.
- Define the clocks: Clocks start on agreed channels; pause only for customer or third‑party waits, with visible timestamps.
- Build escape valves and ownership: Severity 1 (Sev1) commander, incident bridge, and credit/governance paths beat wishful Estimated Time of Arrival (ETA) promises.
- Make behavior measurable: Tie goals to SLA adherence and churn risk; instrument handoffs to eliminate ping‑pong.
Time‑boxed SLAs, realistic buffers, visible clocks, and clear ownership keep momentum high and expectations managed—inside and with customers.
Eliminating Chaos: Hardening Handoffs and Building Measurable Accountability
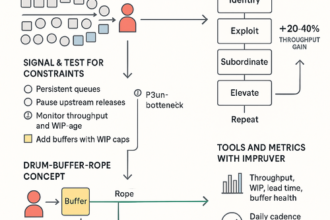
Escalations shouldn’t hijack weeks—they must run as a designed system. Hardened handoffs and data‑backed accountability cut churn and free leadership time.
- Triggers and ownership: Define severities, entry/exit criteria, and one Directly Responsible Individual (DRI) per stage to end ping‑pong.
- Shift‑proof flow: Interoperable queues with checklists and acceptance criteria carry context across teams and shifts.
- SLAs that stick: Set targets tied to capacity and Service Level Objectives (SLOs), with auto‑escalation and clear paths.
- Visible learning: Track acknowledgment and resolve times, reopens, and sentiment; review weekly to improve.
Frictionless handoffs use standard packets, one channel, and customer updates at a predictable cadence so issues move forward—even as teams or shifts change.
Creating Durable, Teachable Processes: Continuous Improvement and Training with Impruver University
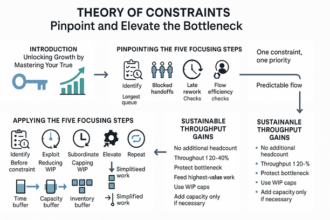
Quick fixes collapse under stress; durable, teachable processes don’t. Structure escalations so problems move—not managers—and revenue stays protected.
- Triggers & Paths: Define severities and automatic routes; map promises to SLOs to stop ping‑pong.
- Ownership: One DRI per incident with explicit handoffs reduces stalls and executive summons.
- SLAs That Hold: Capacity‑based SLAs with buffers; measure TTA/TTR and adherence.
- Standard Operating Procedures (SOPs) + Coaching: One‑page plays plus short after‑action loops drive improvement.
- Role‑Ready Practice: Simulation drills and Impruver University modules build reflexes that stick.
Continuous improvement means you measure TTR, breach causes, and reset thresholds quarterly. Want relief, not heroics? For a CEO‑friendly blueprint, the Lyaxis newsletter distills what works; dedicated training turns it into muscle memory so executive firefighting fades and revenue stays safe.