Designing Real-Time Slack Andon Alerts That Cut Downtime
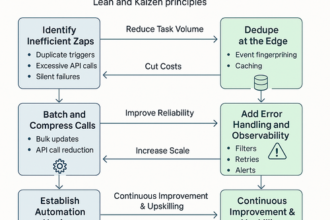
On my first rollout of a Slack-based Andon system (Andon: a lean manufacturing alerting method for signaling problems in real time), I learned fast that downtime is mostly a signal and ownership problem. If you make the signal clear and the owner obvious, response time shrinks. Designed well, Slack Andon cuts MTTA (Mean Time to Acknowledge) quickly and automates clean handoffs so issues do not stall. In this guide, I’ll share the patterns that keep floors calm and uptime steady: define auditable triggers, route alerts with context, automate without noise, and then scale the playbook plant‑wide.
For deeper practice and examples you can put to work on shift change today, I often skim the field notes in the Lyaxis newsletter archive, and use the drills and coursework from Impruver University to turn these patterns into daily habits.
Defining Clear Andon Triggers and Escalation Rules for Reliable Response
Clear, auditable Andon triggers tied to standards—rather than opinion—make response repeatable and fast, cutting both MTTA (Mean Time to Acknowledge) and MTTR (Mean Time to Repair/Restore). Start with what you can measure and prove.
-
Tie triggers to standards and takt
- Takt time: the pace of customer demand that sets the expected production rate.
- Standards remove debate; operators submit a simple form and Slack is notified in seconds.
-
Make triggers numeric and auditable
- E‑Stop (Emergency Stop) held > 30 seconds.
- Output −10% versus takt time for 5 minutes.
- FPY (First Pass Yield) < 98% across 10 pieces.
- Quality drift, scrap, or safety events defined by threshold.
-
Use timed, tiered escalation without spam
- T1 (first-tier) acknowledgment timer set to 60 seconds.
- Escalate to the next tier at 3 minutes; escalate again at 7 minutes.
- Quiet hours and rate limits prevent channel overload.
-
Make accountability visible
- Show named owner, clear SLA (Service Level Agreement) and a visible timer in the alert.
- Track MTTA/MTTR and dwell by shift and line for weekly review.
Result: clear rules remove debate and speed help to the right place at the right time.
Smart Channel Routing and Alert Context to Speed Diagnosis and Ownership
Routing and context determine Andon’s impact in Slack. The right people, with the right information, at the first ping—then the conversation stays in a thread so the channel does not get noisy.
-
Route by line, asset family, severity, and shift role
- Send to dedicated line/asset channels with an on‑call roster by shift.
- Name the primary owner and backup to eliminate ambiguity.
- Use thread‑first alerts to keep the main channel readable.
-
Pack actionable context into the first alert
- Line/asset ID, SKU (Stock Keeping Unit), timestamp, and a photo or fault snapshot.
- Last good run and last change made (material, settings, crew).
- Link or reference to the relevant SOP (Standard Operating Procedure) when applicable.
-
Escalate on time‑to‑ack and risk
- Timers based on severity; critical issues can also roll to a single executive channel.
- Respect quiet hours; bundle similar events to reduce bounce.
-
Make ownership and learning explicit
- “Claim” and “assign” buttons confirm who is working the issue.
- Auto shift‑handoff ensures no issue is stranded at shift change.
- Capture a short post‑mortem in the thread for later review.
Result: lower MTTA/MTTR, less ping‑pong, and safer, steadier uptime.
Reducing Alert Fatigue and Preventing Stalls with Sensible Automation
Noise kills response. Sensible automation protects focus without hiding risk. The goal is to alert once, to the right people, with just enough information to act immediately.
-
Dedupe and add hysteresis to avoid flapping
- Hysteresis: a buffer that requires the state to truly change before another alert fires.
- Suppress repeats until the condition clears and reoccurs beyond a threshold.
-
Use cooldowns and quiet hours tied to takt and SLAs
- Cooldown windows prevent rapid‑fire alerts during instability.
- Escalate only on risk and business impact, not every blip.
-
Auto‑acknowledge and remind before escalating
- Auto‑assign an initial owner in Slack; send gentle reminders if idle.
- Then escalate by role/shift if timers expire.
-
Detect stalls and boost severity with context
- When an issue lingers, include richer context (line, asset, SKU, time, photo) and raise priority.
- Route escalations to the right channel automatically.
Result: faster first responses, fewer stalls, measurable gains in MTTA/MTTR, and a steadier OEE (Overall Equipment Effectiveness).
Scaling Andon Success Across the Plant and Upskilling Through Practical Training
Scale what works: standardize Andon‑to‑Slack so owners act in minutes. Pilot one cell, prove ROI (Return on Investment), then clone the template across lines.
-
Standardize triggers and forms across all lines
- Define auditable thresholds tied to takt time and SLAs (e.g., jam > 120 seconds; FPY < 95%).
- One operator form template feeds every line’s Slack alert.
-
Codify routing, timers, and handoffs
- Route by line/asset/shift to the owner’s channel; auto‑escalate in 3–5 minutes.
- Quiet hours, rate limits, and visible handoffs keep the system calm.
-
Include rich context so the first reply is the fix, not triage
- Line, asset ID, SKU, timestamp, and a photo or fault code snapshot travel with every alert.
-
Measure relentlessly and celebrate wins
- Track MTTA/MTTR and downtime saved by shift and line.
- Spotlight weekly wins to build pull and reinforce good behavior.
-
Invest in practical upskilling to lock in habits
- Use the Lyaxis newsletter for field‑tested patterns and rollout playbooks.
- Turn patterns into daily routines with bite‑size drills from Impruver University.
Result: plant‑wide reliability, fewer stalls, and faster recoveries—without the chaos.