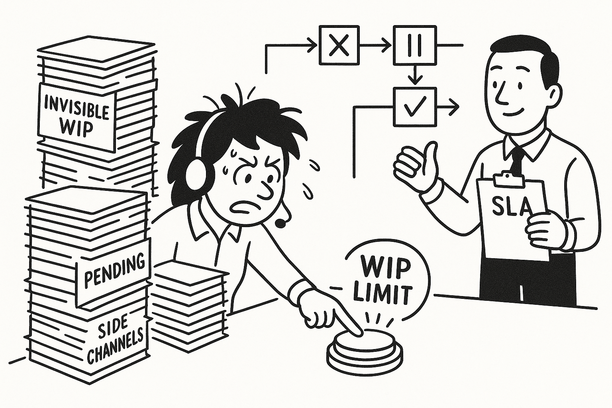
I learned the hard way that most customer waits aren’t about lazy agents or overwhelming volume. Early in my career, I chased handle-time targets and hired more people, yet queues still ballooned. What finally changed outcomes was seeing the invisible work—requests sitting in handoffs, side channels, and “pending-customer” buckets no one owned. Once we exposed and governed that hidden Work‑in‑Progress (WIP), lead times fell, fire drills faded, and promises started to stick.
Introduction: Why Invisible WIP Is the Hidden Culprit Behind Long Customer Waits
In service operations, invisible Work‑in‑Progress (WIP)—not slow agents—makes customers wait. Little’s Law is unforgiving: more WIP means longer lead times, every time. The hidden inventory lurks in handoffs, side channels, and “pending” queues without clear ownership. Add context switching and throughput collapses; triage and queue management protect the most valuable work at risk.
Set WIP limits to shrink queues, and design Service Level Agreements (SLAs) around true capacity. Make queues visible across channels, and track the age of work and blockages to expose bottlenecks. The takeaway: surface WIP, stabilize flow, and lift Customer Satisfaction (CSAT) and predictability without adding headcount.
Mastering Queue Management: Triage Frameworks to Prioritize Value-at-Risk Work
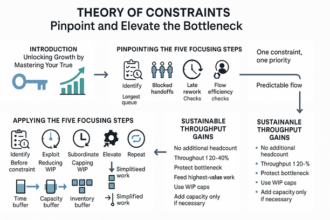
Most long waits in queues aren’t caused by volume—they’re caused by invisible WIP. Teams that triage by value‑at‑risk routinely cut average wait 30–50% because they align attention with what the business can least afford to delay.
- Class of Service clarifies trade‑offs: Use a small set of policies to make priority explicit and auditable.
- Expedite: Scarce, reserved for existential or near‑existential risk; require leadership approval.
- Fixed Date: Time‑bound obligations with clear deadlines and defined breach impact.
- Standard: Default path for routine requests; flow efficiency is the goal.
- Intangible: Risk‑retiring work (for example, defects or debt) that prevents future incidents.
- Define entry/exit criteria and capacity per class: Remove ambiguity; prevent over‑promising.
- Use value‑at‑risk over “who shouts loudest”: Weigh revenue, churn, safety, and regulatory exposure.
- Ration expedite tokens: Limit how many can be in flight to protect flow for everyone else.
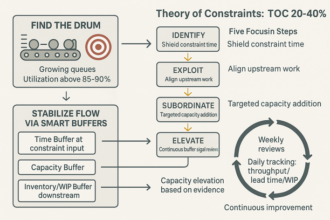
- Match WIP limits to capacity: Stop starting; start finishing to cut lead times.
Example: a Business‑to‑Business (B2B) support team cut backlog 47% and stabilized SLAs in four weeks by enforcing these rules.
WIP Limits and SLA Design: Balancing Capacity, Demand, and Customer Expectations
Excess WIP guarantees slow response, missed SLAs, and falling CSAT. The remedy is to contain what enters the system and set expectations from actual performance, not wishful thinking.
- Triage by value‑at‑risk and route work intentionally: Separate Severity 1/Severity 2 (S1/S2) incidents and “one‑touch” requests solvable in a single interaction; each path gets its own policy and capacity.
- Cap WIP per queue to true capacity: Use observed throughput to set limits; if a lane is full, don’t start new items.
- Design SLAs from the 50th/90th percentile (P50/P90) service times: Publish variability bands and clear renegotiation triggers when demand or mix shifts.
- Hold spike buffers: Keep explicit headroom to absorb predictable surges without breaking promises.
From Data to Decisions: Making Backlog and Flow Visible for Predictable Service
If you can’t see work aging, you can’t keep promises. Visibility turns guesswork into governance.
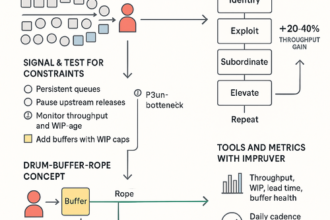
- Cumulative Flow Diagrams (CFDs): Show where arrivals outrun throughput so you can set WIP limits and adjust triage to protect SLAs.
- Aging charts: Surface stuck items; pull the highest value‑at‑risk first and rebalance capacity to clear blockages.
- Control charts: Make lead‑time and response predictions probabilistic; spot drift early and correct before SLAs are breached.
A 60‑agent support team cut waits 40% in five weeks by exposing aging and redesigning SLAs—no additional hiring required.
Relief Pathways: Reducing Wait Times and Firefighting with Practical Upskilling
At around 85% utilization, queues explode and CSAT sinks. Replace firefighting with repeatable relief through disciplined queue management and targeted skills.
- Set triage and WIP limits by class of service: A B2B Software‑as‑a‑Service (SaaS) provider cut waits 42% while protecting SLAs by tightening policies.
- Swarm and cross‑skill for spikes: Lightweight runbooks make fixes repeatable and safe when demand surges.
- Tighten ownership and handoffs: Reduce rework and context switching; prioritize one‑touch resolution where appropriate.
- Design SLAs from actual capacity (per Little’s Law): Surface flow and WIP in simple dashboards to keep promises visible and credible.
The result: calmer teams, predictable responses, and leadership time reclaimed for proactive improvements.
Want steady, practical wins? Get weekly playbooks via the Lyaxis newsletter. When you’re ready to accelerate hands‑on capability building, Impruver University offers practical, applied training—use code 15off.