Introduction: Harnessing AI for Smarter Exception Handling and Faster MTTR
On my last on‑call rotation, a single noisy deploy fanned out into dozens of pages across services. We weren’t short on skill; we were short on signal. After we layered artificial intelligence (AI) to cluster repeat exceptions, enrich alerts, and trigger guardrailed runbooks, our mean time to resolution (MTTR) — the average time it takes to restore service — fell by roughly 35%. Exception noise is up while on‑call capacity is flat; the teams that win are using AI to classify patterns, add missing context, and trigger safe fixes that protect service‑level agreements (SLAs).
In practice, that looks like auto‑classifying recurring errors to the right owner or a pre‑approved runbook in seconds, enriching alerts with deploy diffs, logs, and feature flags to end blind triage, and triggering guarded remediation with rollbacks, rate limits, and full audit trails.
Decoding Failure Patterns: How AI Auto‑Classifies and Prioritizes Incidents
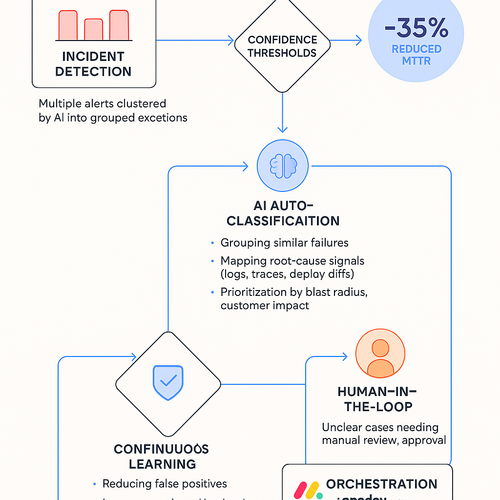
AI can turn noisy incidents into clear, prioritized work. By clustering repeat exceptions and scoring urgency, teams fix what matters first, protect SLAs, and consistently cut MTTR in low‑risk pilots.
- Group similar failures across services: shrink alert storms by clustering duplicate or related exceptions.
- Map root‑cause signals: fuse logs, traces, and recent changes to reduce blind handoffs.
- Rank by blast radius and customer impact: prioritize real user harm over pager volume.
- Auto‑classify recurring errors: route to the right owner or a pre‑approved runbook within seconds.
- Enrich alerts with context: attach deploy diffs, logs, and feature‑flag states to end guesswork.
- Learn from outcomes: continuously lower false positives as remediations succeed or fail.
Result: fewer escalations, steadier SLAs, and leadership time back as swarms become exceptions rather than habit.
Safe, Automated Remediation: Triggering Confident Actions Without Manual Overhead
Recurring exceptions don’t need humans on every page. Guardrailed AI automation classifies repeat failures and triggers pre‑approved fixes — often cutting MTTR by about 35% while protecting SLAs.
- Confidence thresholds and policy: execute only verified runbooks when signals align.
- Human‑in‑the‑loop on ambiguity: inline approvals for unclear cases maintain control.
- Reversible actions first: toggle feature flags, roll back risky changes, or clear caches safely.
- Rate limits and blast‑radius checks: ensure remediations can’t overwhelm systems.
- Live observability and immutable audit trails: see what ran, when, and why — and prove compliance.
Start with low‑risk pilots and expand as evidence builds; each successful auto‑resolve earns trust for the next step.
Orchestrating Reliability: Using Monday.com Playbooks to Streamline Incident Response
Incidents drain focus and trust. Monday.com playbooks align alerts, owners, and SLAs so swarms, updates, and aftercare happen in one place — freeing leaders from firefighting.
- Auto‑assign and surface context: changes, logs, and runbooks appear where owners work, slashing handoffs.
- Trigger pre‑approved remediations: guarded actions run with approvals and full audit trails.
- Unify the incident timeline: correlate signals to expose patterns that drive durable prevention.
- Orchestrate signals and ownership: reduce swivel‑chair ops by coordinating response in a single playbook.
If you’re formalizing playbooks or scaling what already works, explore how Monday.com can centralize signals and actions to cut triage time and MTTR. Try it here: Monday.com playbooks.
Next Steps: Starting Low‑Risk Automation Pilots to Free Leadership and Boost Trust
Start with reversible pilots that auto‑classify recurring exceptions and trigger safe, pre‑approved fixes. The aim: cut MTTR by ~35% and return focus time to leadership.
- Guardrails: pre‑approved remediations, human‑in‑the‑loop on ambiguity, automatic rollbacks, and full audits.
- Metrics that matter: track MTTR (mean time to resolution), false‑positive rate, and auto‑resolves; share weekly micro‑wins.
- Orchestrate in Monday.com: consolidate signals, auto‑route owners, and trigger playbooks to end brittle scripts and handoffs.
- Target the loudest pain first: pick the top three noisy patterns, auto‑classify and remediate, then expand on proven gains.
Want the patterns, not the hype? Lyaxis distills proven playbooks and Monday.com mappings in a short, insight‑first newsletter — so your team focuses on impact, not noise. Subscribe here: Lyaxis Newsletter.